 Datenschutzeinstellungen
Datenschutzeinstellungen Verstreute Daten, verlorenes Wissen – So löst ihr isolierte Dateninseln auf
Großunternehmen stehen vor einer besonderen Herausforderung: Sie pflegen große Datenbestände, die für den alltäglichen Betrieb und die Unternehmensführung unerlässlich sind – können sie aber nicht so einfach miteinander verbinden. Die Daten liegen isoliert in unterschiedlichen Abteilungen vor. Sie werden in verschiedensten Formaten erfasst (Excel, Access) und verwaltet – ohne Berücksichtigung darauf, dass diese Daten auch für andere Teams wertvoll sein könnten. Diese sogenannten Datensilos (isolierten Datenbestände), verhindern den einfachen Austausch von Informationen.
Das betrifft besonders solche Unternehmen, die mehrere spezialisierte Informationssysteme – wie z.B. geografische Informationssysteme (GIS) – parallel nutzen. Die Herausforderungen, die mit Datensilos einhergehen, betreffen nicht nur die einzelnen Abteilungen – sie betreffen das gesamte Unternehmen.
In diesem Blogbeitrag beleuchten wir genauer, was Datensilos sind, warum sie problematisch werden können und wie wir sie mithilfe einer Datenintegrations-Plattform effizient auflösen, um die Daten miteinander zu verbinden.
Die Wissensplattform Springer Professional liefert eine treffende Definition zu diesem häufigen Problem in Unternehmen:
Von einem Datensilo wird gesprochen, wenn Daten an verschiedenen Orten in einem Unternehmen gespeichert sind und nur gewisse organisatorische Bereiche auf diese Daten Zugriff haben. [Springer Professional]
Datensilos entstehen, wenn Daten in einem Unternehmen isoliert an verschiedenen Orten gespeichert werden und nur bestimmten Teams, Abteilungen oder Personen zugänglich sind. Oftmals liegen diese Daten in unterschiedlichen Formaten oder Systemen vor, die nicht miteinander kompatibel sind. Das Resultat: Wertvolle Informationen, die eigentlich dem gesamten Unternehmen nützen könnten, bleiben ungenutzt oder stehen nur einem kleinen Kreis zur Verfügung.
Bestes Bespiel: Raumsonde Absturz
1999 stürzte die NASA-Raumsonde Mars Climate Orbiter spektakulär ab — ein 125-Millionen-Dollar-Projekt, buchstäblich in Rauch aufgelöst, aber warum?
Weil zwei Teams in unterschiedlichen Maßeinheiten arbeiteten: Das eine Team nutzte das metrische System, das andere das imperiale. Die fatalen Missverständnisse in der Datenübersetzung führten dazu, dass die Sonde anstatt in die Umlaufbahn zu gelangen, in die Marsatmosphäre eintauchte und verbrannte.
Was wie ein Weltraumdrama klingt, passiert in abgewandelter Form täglich in Unternehmen. Unterschiedliche Abteilungen speichern Daten in eigenen Formaten — sei es Excel, Access, oder spezialisierte GIS-Systeme — und selbst einfache Werte wie Längenangaben können verschieden gehandhabt werden. Ohne ein zentrales Übersetzungs- und Integrationswerkzeug entstehen Missverständnisse und die Zusammenarbeit gerät ins Stocken.
Datensilos scheinen auf den ersten Blick vielleicht nur ein technisches Problem zu sein, in der Realität beeinträchtigen sie jedoch die Fähigkeit des gesamten Unternehmens, fundierte Entscheidungen zu treffen und effektiv zusammenzuarbeiten.

Eine Methode zur Vermeidung von Datensilos besteht darin, abteilungsübergreifende Zusammenarbeit von Anfang an zu fördern und Richtlinien für die gemeinsame Datennutzung zu etablieren. Dieser Ansatz ist oft schwer durchzusetzen und erfordert kontinuierliche Abstimmung.
Besonders in größeren Unternehmen, in denen Abteilungen unterschiedliche Prioritäten und Arbeitsabläufe haben, ist die Implementierung solcher Richtlinien eine Herausforderung. Häufig fehlen standardisierte Prozesse, die sicherstellen, dass Daten systematisch geteilt und gepflegt werden, was dazu führt, dass Informationen dennoch isoliert bleiben. Abteilungen oder Teams sind möglicherweise nicht bereit, ihre Daten zu teilen, entweder aufgrund von Bedenken hinsichtlich der Datensicherheit oder aus Angst, Kontrolle über ihre Informationen zu verlieren. Dies führt oft dazu, dass die notwendigen Schritte zur Vermeidung von Datensilos vernachlässigt oder umgangen werden.
Selbst wenn Richtlinien erfolgreich eingeführt werden, ist die manuelle Pflege und Koordination von Datenflüssen zeitaufwendig und fehleranfällig. Änderungen in den Datenquellen, wie z.B. neue Formate oder aktualisierte Systeme, müssen fortlaufend berücksichtigt werden, um eine konsistente und aktuelle Datenbasis zu gewährleisten. Ohne Automatisierung oder geeignete technische Unterstützung erfordert dies ein hohes Maß an Aufwand und eine regelmäßige Überprüfung.
Diese technischen Herausforderungen sind manuell nur schwer zu bewältigen und können die abteilungsübergreifende Zusammenarbeit letztlich behindern.
Eine praktikablere und kosteneffizientere Lösung ist die Integration der Daten durch automatisierte Datenpipelines.
Datenpipelines ermöglichen es, Daten aus verschiedenen Quellen und Formaten zusammenzuführen, sie in ein einheitliches und nutzbares Format zu konvertieren und sie an einem zentralen Ort zur Verfügung zu stellen.
Die Automatisierung reduziert manuelle Eingriffe und minimiert Fehler, was die Datenkonsistenz erhöht.
Die Vorteile automatisierter Datenpipelines sind klar:
Trotz dieser Vorteile ist die Implementierung solcher Pipelines oft mit Herausforderungen verbunden. Diese Herausforderungen betreffen nicht nur die technische Komplexität, sondern auch die Datenformate, die Flexibilität der Integration und die langfristigen Kosten.
Vielfalt der Datenquellen und Formate
Daten aus verschiedenen Systemen wie GIS, ERP oder CRM haben oft nicht nur unterschiedliche Formate, sondern auch abweichende Strukturen und Bezeichnungen. Um sie sinnvoll zu integrieren, müssen sie inhaltlich harmonisiert werden, damit eine nutzbare Datenbasis entsteht.
Hohe Kosten und Ressourcenbedarf
Die Entwicklung und Wartung individueller Datenintegrationslösungen erfordert erheblichen finanziellen und personellen Aufwand. Unternehmen müssen Zeit und Budget investieren, um die Lösungen dauerhaft aktuell und funktionsfähig zu halten.
Alte Datenbestände und technische Schulden
Isolierte und über Jahre hinweg veraltete Datensätze erschweren den Integrationsprozess erheblich. Solche Datenbestände müssen oft zunächst aufbereitet und konsolidiert werden, was zusätzlichen Aufwand und Kosten verursacht.
Begrenzte Tool-Unterstützung
Viele Integrationswerkzeuge sind auf Datenformate und -quellen begrenzt. Oft stellen sich während eines Projekts unerwartete Anforderungen heraus, die das eingesetzte Tool nicht abdeckt. Dann sind zusätzliche Technologien erforderlich, die den Aufwand erhöhen.
Komplexität der eingesetzten Tools
Viele Integrationswerkzeuge sind äußerst komplex und erfordern ein tiefgehendes technisches Verständnis, um sie effektiv nutzen zu können. Ohne erfahrene und kompetente Entwickler kann die Einarbeitung in solche Tools sehr zeitaufwendig sein und den Projektfortschritt verzögern.
Unvollständige und fehlerhafte Daten
Daten aus unterschiedlichen Quellen enthalten häufig Fehler, Inkonsistenzen oder Lücken. Diese müssen vor der Integration bereinigt und validiert werden, um zuverlässige und konsistente Informationen zu gewährleisten.
Diese Herausforderungen machen deutlich, dass Datenpipelines und Datenintegration zwar eine effektive Lösung für Datensilos sein können, in der Praxis jedoch oft mit hohem Aufwand verbunden sind. Viele Tools stoßen dabei an ihre Grenzen, da sie nicht flexibel genug sind, zu wenige Anpassungsmöglichkeiten bieten oder nicht alle relevanten Datenformate unterstützen. Wir setzen daher auf ein leistungsstarkes und intuitives Tool, das genau diese Schwächen ausgleicht. Im nächsten Kapitel stellen wir es genauer vor – inklusive der persönlichen Einschätzung unseres Experten, der es seit Jahren erfolgreich einsetzt.
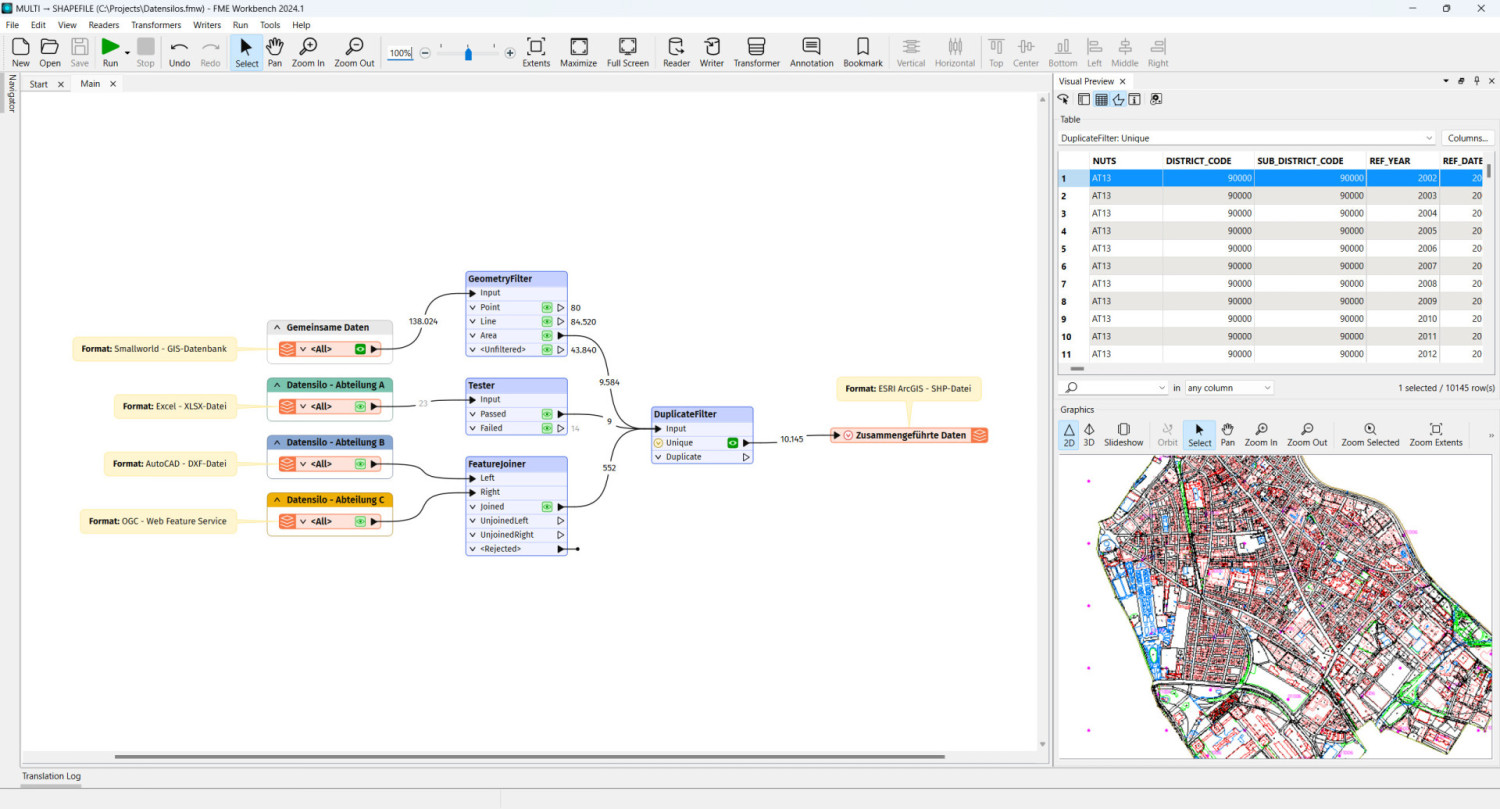
Wir stellen vor: FME, die Datenintegrationsplattform von Safe Software.
Was FME von anderen Datenintegrations-Tools abhebt, ist nicht nur die Fähigkeit, Daten zu verarbeiten, zu transformieren und zu integrieren – das können viele Plattformen. Der wahre Vorteil von FME liegt in seiner außergewöhnlichen Vielseitigkeit: Es unterstützt über 450 Datenformate und -quellen, darunter auch spezialisierte und nischenhafte Systeme, die vor allem in der Energie- und Industriebranche essenziell sind.
Während viele Integrationslösungen auf gängige Daten wie Excel, CSV oder Standard-Datenbanken begrenzt sind, geht FME weit darüber hinaus. Es ermöglicht die Verarbeitung hochspezifischer Datenquellen wie SCADA-Systeme, GIS-Anwendungen wie ArcGIS oder Smallworld, CAD-Programme sowie komplexe Datenbanken und IoT-Daten. Gerade für Unternehmen, die auf diese spezialisierten Systeme angewiesen sind, bietet FME eine Lösung, die ihresgleichen sucht.
Frage: Daniel, du arbeitest schon seit vielen Jahren mit FME. Wie bist du ursprünglich mit dem Tool in Berührung gekommen?
Daniel: Das war tatsächlich direkt ab Tag 1, als ich bei Plincs angefangen habe. FME war damals schon ein wichtiger Bestandteil unserer Projekte. Am Anfang habe ich vor allem kleinere GIS-Projekte betreut. Aber je mehr ich mit FME gearbeitet habe, desto klarer wurde mir, wie vielseitig das Tool eigentlich ist. Mittlerweile nutze ich es für ganz unterschiedliche Anwendungsfälle und Datenformate. Man könnte fast sagen, dass ich in so gut wie jedem Projekt auf FME zurückgreife, weil es so viele Probleme ganz unkompliziert lösen kann.
Frage: Was macht FME für dich so besonders?
Daniel: Die Vielseitigkeit. Man kann damit wirklich alles Mögliche anstellen. Egal, ob es darum geht, Daten aus verschiedenen Formaten zusammenzuführen, Daten zu transformieren oder Workflows zu automatisieren – FME deckt das alles ab. Es unterstützt unglaublich viele Datenformate, und das schließt auch viele Nischenformate ein, die gerade in der Industrie und Energiebranche wichtig sind. Oft sehe ich Entwickler, die sich mit komplizierten Lösungen abmühen, und ich denke mir: Mit FME wäre das in ein paar Stunden erledigt.
Frage: Kannst du uns ein konkretes Beispiel aus deiner Arbeit mit FME geben?
Daniel: Klar! Unser erstes Projekt mit FME war eher klein, aber danach haben wir für einen Großkonzern gearbeitet, der unzählige Datenbanken und Formate im Einsatz hatte. Da ging es um alles: Stationen, Trafos, Trafospulen – die komplette Modellierung der Daten. Wir haben alles mit FME umgesetzt. Das hat nicht nur super funktioniert, sondern war auch verständlich für alle Beteiligten und einfach zu bedienen.
Ein anderes Beispiel: Ein Kunde hatte mehrere Systeme, die nicht miteinander kommunizieren konnten. Da habe ich mit FME eine Lösung gebaut, die diese Systeme verbindet, ohne sie auszusetzen. Die Systeme laufen weiterhin wie gewohnt, die Abteilungen arbeiten wie bisher, aber wir haben die Daten zentralisiert und synchronisiert – stündlich, minütlich, je nachdem, was der Kunde benötigt.
Frage: FME klingt nach einem mächtigen Werkzeug. Kannst du etwas zu den Einstiegsmöglichkeiten sagen?
Daniel: Der Einstieg mit FME ist wirklich angenehm. Das Tool ist so gestaltet, dass man recht schnell die Übersicht über die Daten und Workflows bekommt. Auch wenn jemand keine Programmierkenntnisse hat, kann er mit FME arbeiten. Die grafische Benutzeroberfläche macht es super einfach. Aber natürlich kann man auch eigene Skripte einbauen, wenn man mehr Flexibilität braucht.
Frage: Ihr helft Kunden also nicht nur, FME-Lösungen zu bauen, sondern gebt ihnen auch die Möglichkeit, selbst damit zu arbeiten?
Daniel: Genau. Wir bauen oft die Grundstruktur für die Kunden, sei es ein Workspace oder eine Datenpipeline, und helfen ihnen, die ersten Schritte zu machen. Aber viele Kunden können danach eigenständig mit FME arbeiten. Natürlich sind wir immer da, wenn sie Hilfe brauchen oder neue Anforderungen haben. Das Tolle an FME ist, dass es so leicht zu verstehen ist, dass Kunden es nach einer kurzen Einarbeitung selbst in die Hand nehmen können.
Frage: Du bildest dich auch regelmäßig weiter. Welche Rolle spielt das für deine Arbeit?
Daniel: Eine große. Ich fahre jedes Jahr zur FME-Konferenz, um auf dem neuesten Stand zu bleiben. Dort lerne ich nicht nur, wie FME weiterentwickelt wird, sondern bekomme auch Einblicke in riesige Projekte und kreative Anwendungsfälle aus der Community. Was ich an FME wirklich schätze, ist, dass sie sehr offen für Feedback sind. Sie hören auf ihre Nutzer und entwickeln das Tool kontinuierlich weiter. Das motiviert natürlich auch, selbst immer besser zu werden.
Frage: Welche Arten von Kundenprojekten betreut ihr typischerweise mit FME?
Daniel: Es gibt zwei Hauptfälle, die wir oft sehen. Zum einen kommen Kunden zu uns, die ein altes System haben und auf ein neues umsteigen möchten. Dabei wollen sie natürlich ihre bestehenden Daten behalten. Da machen wir dann oft Reverse Engineering: Wir analysieren alte Daten und Codes, lesen sie aus und übertragen sie ins neue System.
Zum anderen gibt es Kunden, die mehrere Systeme gleichzeitig im Einsatz haben, die nicht miteinander „reden“ können. Hier setzen wir FME ein, um die Daten zwischen diesen Systemen zu übersetzen. Die Systeme selbst müssen nicht verändert werden, und die Abteilungen können wie gewohnt arbeiten. Die Daten werden zentralisiert und synchronisiert – das kann jede Stunde, jede Minute oder nur bei Bedarf passieren.
Frage: Gibt es etwas, das dich bei der Arbeit mit Kunden und FME immer wieder überrascht?
Daniel: Ja, eine Sache fällt mir immer wieder auf: Wenn man länger an einem Projekt arbeitet und tiefer ins Unternehmen eintaucht, merkt man, dass viel mehr Abteilungen und Leute betroffen sind, als ursprünglich angenommen. Diese verschiedenen Abteilungen führen automatisch dazu, dass man auch mit mehr Daten von diesen verschiedenen Abteilungen arbeiten muss. Das sind Datensilos.
Frage: Was würdest du Unternehmen raten, die sich für FME interessieren?
Daniel: Einfach ausprobieren. Viele Unternehmen wissen gar nicht, was alles möglich ist, bis sie FME in Aktion sehen. Und wer sich nicht sicher ist, wie er starten soll, kann uns gerne kontaktieren. Wir helfen nicht nur beim Einstieg, sondern unterstützen auch bei komplexen Projekten. FME ist wirklich ein Game-Changer, wenn es darum geht, Daten sinnvoll zu integrieren und zu nutzen.
Umfassende Formatunterstützung: Über 450 Datenformate, inklusive spezialisierter Systeme wie SCADA, GIS (ArcGIS, Smallworld).
Intuitive Bedienbarkeit: Grafische Oberfläche für einfache Workflows, aber flexibel genug für Entwickleranpassungen.
Skalierbarkeit & Modularität: Für kleine und große Projekte, Workflows lassen sich schrittweise erweitern.
Automatisierung & Effizienz: Vollautomatische Datenprozesse halten Daten aktuell und reduzieren manuellen Aufwand.
Datensilos sind mehr als nur ein technisches Hindernis – sie wirken sich direkt auf die Effizienz, Entscheidungsfindung und Innovationskraft eines Unternehmens aus. Während das Asset-Management Daten zu Wartungszyklen speichert, hält das GIS-System räumliche Informationen bereit, und das ERP-System verwaltet Betriebsprozesse. Doch diese Systeme sprechen nicht miteinander, wodurch wertvolle Zusammenhänge verloren gehen. Unternehmen riskieren ineffiziente Arbeitsprozesse, höhere Kosten und verpasste Chancen.
Die Integration von Daten ist daher kein „Nice-to-Have“, sondern ein entscheidender Wettbewerbsvorteil in der modernen Unternehmenswelt.
Datenpipelines sind ein erster Schritt, um Datenflüsse zu automatisieren und eine einheitliche Basis zu schaffen. Doch sie stoßen an Grenzen, wenn unterschiedlichste Formate, komplexe Systemlandschaften und sich ständig ändernde Anforderungen ins Spiel kommen. Genau hier setzt FME an. Im Gegensatz zu herkömmlichen Datenpipelines ist FME nicht nur ein Verbindungsstück zwischen Systemen, sondern eine leistungsstarke und anpassbare Plattform zur Datenverarbeitung.
Ein Tool allein reicht nicht aus – die richtige Strategie und Umsetzung sind entscheidend. Mit unserer langjährigen Erfahrung in der Datenintegration und unserem tiefen Verständnis für FME helfen wir Unternehmen dabei, ihre Datensilos aufzulösen und eine zentrale, vernetzte Datenbasis zu schaffen. Bestehende Datenquellen – wie GIS, SCADA oder Asset Management – verknüpfen wir effizient miteinander. Dabei erstellen wir maßgeschneiderte Workflows, die automatisiert und ereignisbasiert ausgeführt werden.
Was bedeutet das für euer Unternehmen?
Effizientere Prozesse: Weniger manuelle Arbeit, mehr Automatisierung.
Höhere Datenqualität: Einheitliche, bereinigte und aktuelle Informationen.
Bessere Entscheidungsgrundlage: Transparente, zentral verfügbare Daten.
Flexibilität und Zukunftssicherheit: Datenstrukturen, die sich anpassen lassen.
Ihr wollt eure Daten effizient vernetzen und das volle Potenzial eurer Systeme ausschöpfen?
Wir stehen euch als FME-Experten zur Seite – von der ersten Analyse bis zur Umsetzung maßgeschneiderter Integrationslösungen.
Kontaktiert uns gerne hier – wir beraten euch!
Bleibt auf dem Laufenden und vernetzt euch mit uns!
Wenn ihr unseren Blog inspirierend findet und noch öfter in unsere Welt eintauchen möchtet, dann folgt uns auf Social Media. Wir teilen dort regelmäßig Einblicke, Neuigkeiten und die kleinen Freuden unseres Entwickleralltags.
👉 Folgt uns auf LinkedIn und Facebook oder schreib uns eine Mail an office@plincs.com.
Plincs
Links
Systems